WebGPU API
WebGPU API 使 Web 開發者能夠使用底層系統的 GPU(圖形處理器)執行高效能計算,並繪製可在瀏覽器中渲染的複雜影像。
WebGPU 是 WebGL 的後繼者,它提供了與現代 GPU 更好的相容性,支援通用 GPU 計算,更快的操作,以及訪問更高階的 GPU 功能。
概念與用法
可以說,WebGL 在 2011 年左右首次出現後,在圖形能力方面徹底改變了 Web。WebGL 是 OpenGL ES 2.0 圖形庫的 JavaScript 移植,允許網頁將渲染計算直接傳遞給裝置的 GPU,以極高的速度進行處理,並將結果渲染到 <canvas> 元素中。
WebGL 和用於編寫 WebGL 著色器程式碼的 GLSL 語言很複雜,因此建立了幾個 WebGL 庫來簡化 WebGL 應用程式的編寫:流行的例子包括 Three.js、Babylon.js 和 PlayCanvas。開發者利用這些工具構建了沉浸式 Web 3D 遊戲、音樂影片、培訓和建模工具、VR 和 AR 體驗等。
然而,WebGL 存在一些需要解決的根本問題
- 自 WebGL 釋出以來,新一代原生 GPU API 已經出現——最流行的是 Microsoft 的 Direct3D 12、Apple 的 Metal 和 Khronos Group 的 Vulkan——它們提供了許多新功能。OpenGL(以及因此 WebGL)不再計劃更新,因此它將無法獲得這些新功能。另一方面,WebGPU 將不斷新增新功能。
- WebGL 完全基於繪製圖形並將其渲染到畫布的使用場景。它不能很好地處理通用 GPU (GPGPU) 計算。GPGPU 計算對於許多不同的使用場景越來越重要,例如基於機器學習模型的場景。
- 3D 圖形應用程式的要求越來越高,無論是同時渲染的物件數量,還是新渲染功能的使用。
WebGPU 解決了這些問題,提供了一個與現代 GPU API 相容的更新的通用架構,感覺更“web 化”。它支援圖形渲染,但也對 GPGPU 計算提供一流的支援。在 CPU 端渲染單個物件的成本顯著降低,並且它支援現代 GPU 渲染功能,例如基於計算的粒子和後處理濾鏡,如顏色效果、銳化和景深模擬。此外,它還可以直接在 GPU 上處理昂貴的計算,例如剔除和蒙皮模型變換。
通用模型
裝置 GPU 和執行 WebGPU API 的 Web 瀏覽器之間有幾個抽象層。在開始學習 WebGPU 時瞭解這些抽象層很有用
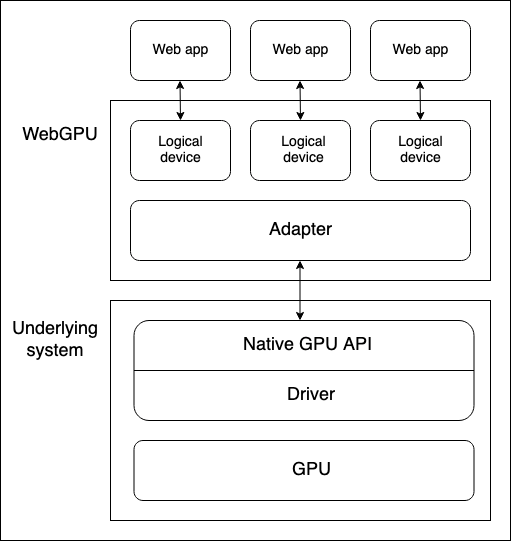
-
物理裝置有 GPU。大多數裝置只有一個 GPU,但有些裝置有多個。有不同的 GPU 型別可用
- 整合 GPU,它與 CPU 在同一主機板上,並共享其記憶體。
- 獨立 GPU,它有自己的獨立主機板,與 CPU 分開。
- 在 CPU 上實現的軟體“GPU”。
注意:上圖假設裝置只有一個 GPU。
-
原生 GPU API 是作業系統的一部分(例如 macOS 上的 Metal),它是一個程式設計介面,允許原生應用程式使用 GPU 的功能。API 指令透過驅動程式傳送到 GPU(並接收響應)。一個系統可能擁有多個可用於與 GPU 通訊的原生 OS API 和驅動程式,儘管上圖假設裝置只有一個原生 API/驅動程式。
-
瀏覽器的 WebGPU 實現透過原生 GPU API 驅動程式處理與 GPU 的通訊。WebGPU 介面卡在您的程式碼中有效地表示底層系統上可用的物理 GPU 和驅動程式。
-
邏輯裝置是一種抽象,透過它單個 Web 應用程式可以以隔離的方式訪問 GPU 功能。邏輯裝置需要提供多路複用能力。物理裝置的 GPU 同時被許多應用程式和程序使用,包括可能許多 Web 應用程式。每個 Web 應用程式需要能夠獨立訪問 WebGPU,出於安全和邏輯原因。
訪問裝置
邏輯裝置(由 GPUDevice 物件例項表示)是 Web 應用程式訪問所有 WebGPU 功能的基礎。訪問裝置如下
Navigator.gpu屬性(如果您在 Worker 中使用 WebGPU 功能,則是WorkerNavigator.gpu)返回當前上下文的GPU物件。- 您透過
GPU.requestAdapter()方法訪問介面卡。此方法接受一個可選的設定物件,允許您請求例如高效能或低能耗介面卡。如果未包含此物件,裝置將提供對預設介面卡的訪問,這對於大多數用途來說已經足夠。 - 可以透過
GPUAdapter.requestDevice()請求裝置。此方法也接受一個選項物件(稱為描述符),可用於指定邏輯裝置應具有的精確功能和限制。如果未包含此物件,則提供的裝置將具有合理的通用規範,這對於大多數用途來說已經足夠。
結合一些功能檢測檢查,上述過程可以透過以下方式實現
async function init() {
if (!navigator.gpu) {
throw Error("WebGPU not supported.");
}
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) {
throw Error("Couldn't request WebGPU adapter.");
}
const device = await adapter.requestDevice();
// …
}
管線和著色器:WebGPU 應用程式結構
管線是一個邏輯結構,包含可程式設計階段,用於完成程式的任務。WebGPU 目前能夠處理兩種型別的管線
-
渲染管線渲染圖形,通常渲染到
<canvas>元素中,但它也可以在螢幕外渲染圖形。它有兩個主要階段-
頂點階段,其中頂點著色器接受輸入到 GPU 的定位資料,並使用它透過應用指定的旋轉、平移或透視等效果在 3D 空間中定位一系列頂點。然後,頂點被組裝成三角形等基本圖形(渲染圖形的基本構建塊),並由 GPU 進行光柵化,以確定每個三角形應覆蓋繪圖畫布上的哪些畫素。
-
片段階段,其中片段著色器計算由頂點著色器生成的原始圖形覆蓋的每個畫素的顏色。這些計算通常使用影像(以紋理形式)作為輸入,提供表面細節以及虛擬光源的位置和顏色。
-
-
計算管線用於通用計算。計算管線包含一個計算階段,其中計算著色器接受通用資料,在指定數量的工作組中並行處理,然後將結果返回到一個或多個緩衝區中。緩衝區可以包含任何型別的資料。
上面提到的著色器是由 GPU 處理的指令集。WebGPU 著色器使用一種低階 Rust 類語言編寫,稱為 WebGPU 著色語言 (WGSL)。
有幾種不同的方法可以構建 WebGPU 應用程式,但該過程可能包含以下步驟
- 建立著色器模組:用 WGSL 編寫著色器程式碼並將其打包到一個或多個著色器模組中。
- 獲取並配置畫布上下文:獲取
<canvas>元素的webgpu上下文,並將其配置為從 GPU 邏輯裝置接收要渲染的圖形資訊。如果您的應用程式沒有圖形輸出,例如只使用計算管線的應用程式,則此步驟不是必需的。 - 建立包含資料的資源:您希望由管線處理的資料需要儲存在 GPU 緩衝區或紋理中,以便您的應用程式可以訪問。
- 建立管線:定義管線描述符,詳細描述所需的管線,包括所需的資料結構、繫結、著色器和資源佈局,然後從中建立管線。我們的基本演示只包含一個管線,但非平凡的應用程式通常會包含多個用於不同目的的管線。
- 執行計算/渲染通道:這涉及一些子步驟
- 建立命令編碼器,它可以編碼一組要傳遞給 GPU 執行的命令。
- 建立通道編碼器物件,在其上發出計算/渲染命令。
- 執行命令以指定要使用的管線,從哪個緩衝區獲取所需資料,要執行多少繪圖操作(對於渲染管線),等等。
- 完成命令列表並將其封裝在命令緩衝區中。
- 透過邏輯裝置的命令佇列將命令緩衝區提交給 GPU。
在下面的部分中,我們將研究一個基本的渲染管線演示,讓您瞭解它需要什麼。稍後,我們還將研究一個基本計算管線示例,瞭解它與渲染管線的區別。
基本渲染管線
在我們的基本渲染演示中,我們給一個<canvas>元素一個純藍色背景,並在其上繪製一個三角形。
建立著色器模組
我們正在使用以下著色器程式碼。頂點著色器階段(@vertex 塊)接受一塊包含位置和顏色的資料,根據給定位置定位頂點,插值顏色,然後將資料傳遞給片段著色器階段。片段著色器階段(@fragment 塊)接受來自頂點著色器階段的資料,並根據給定顏色為頂點著色。
const shaders = `
struct VertexOut {
@builtin(position) position : vec4f,
@location(0) color : vec4f
}
@vertex
fn vertex_main(@location(0) position: vec4f,
@location(1) color: vec4f) -> VertexOut
{
var output : VertexOut;
output.position = position;
output.color = color;
return output;
}
@fragment
fn fragment_main(fragData: VertexOut) -> @location(0) vec4f
{
return fragData.color;
}
`;
注意:在我們的演示中,我們將著色器程式碼儲存在模板字面量中,但您可以將其儲存在任何可以輕鬆作為文字檢索並輸入到 WebGPU 程式的地方。例如,另一個常見的做法是將著色器儲存在 <script> 元素中,並使用 Node.textContent 檢索內容。用於 WGSL 的正確 MIME 型別是 text/wgsl。
要使您的著色器程式碼可用於 WebGPU,您必須將其放入 GPUShaderModule 中,透過呼叫 GPUDevice.createShaderModule(),並將您的著色器程式碼作為描述符物件中的屬性傳遞。例如
const shaderModule = device.createShaderModule({
code: shaders,
});
獲取並配置畫布上下文
在渲染管線中,我們需要指定一個渲染圖形的地方。在這種情況下,我們正在獲取對螢幕 <canvas> 元素的引用,然後呼叫 HTMLCanvasElement.getContext(),引數為 webgpu,以返回其 GPU 上下文(一個 GPUCanvasContext 例項)。
從那裡,我們透過呼叫 GPUCanvasContext.configure() 配置上下文,向其傳遞一個選項物件,其中包含渲染資訊將來自的 GPUDevice、紋理的格式,以及渲染半透明紋理時使用的 alpha 模式。
const canvas = document.querySelector("#gpuCanvas");
const context = canvas.getContext("webgpu");
context.configure({
device,
format: navigator.gpu.getPreferredCanvasFormat(),
alphaMode: "premultiplied",
});
注意:確定紋理格式的最佳實踐是使用 GPU.getPreferredCanvasFormat() 方法;這會為使用者的裝置選擇最有效的格式(bgra8unorm 或 rgba8unorm)。
建立緩衝區並將我們的三角形資料寫入其中
接下來,我們將以 WebGPU 程式可以使用的形式提供資料。我們的資料最初以 Float32Array 提供,其中包含每個三角形頂點 8 個數據點——X、Y、Z、W 用於位置,R、G、B、A 用於顏色。
const vertices = new Float32Array([
0.0, 0.6, 0, 1, 1, 0, 0, 1, -0.5, -0.6, 0, 1, 0, 1, 0, 1, 0.5, -0.6, 0, 1, 0,
0, 1, 1,
]);
然而,這裡有一個問題。我們需要將資料放入 GPUBuffer 中。在幕後,這種型別的緩衝區儲存在與 GPU 核心緊密整合的記憶體中,以實現所需的高效能處理。附帶效應是,主機系統(如瀏覽器)上執行的程序無法訪問此記憶體。
透過呼叫 GPUDevice.createBuffer() 建立 GPUBuffer。我們給它一個等於 vertices 陣列長度的大小,以便它可以包含所有資料,以及 VERTEX 和 COPY_DST 用途標誌,以指示緩衝區將用作頂點緩衝區和複製操作的目標。
const vertexBuffer = device.createBuffer({
size: vertices.byteLength, // make it big enough to store vertices in
usage: GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST,
});
我們可以使用對映操作將資料寫入 GPUBuffer,就像我們在計算管線示例中用於將資料從 GPU 讀取回 JavaScript 一樣。然而,在這種情況下,我們將使用方便的 GPUQueue.writeBuffer() 方法,該方法將其引數作為要寫入的緩衝區、要從中寫入的資料來源、每個的偏移值以及要寫入的資料大小(我們已指定陣列的整個長度)。然後瀏覽器會找出處理資料寫入的最有效方式。
device.queue.writeBuffer(vertexBuffer, 0, vertices, 0, vertices.length);
定義和建立渲染管線
現在我們已經將資料放入緩衝區,設定的下一步是實際建立我們的管線,準備好用於渲染。
首先,我們建立一個物件來描述我們的頂點資料所需的佈局。這完美地描述了我們之前在 vertices 陣列和頂點著色器階段中看到的內容——每個頂點都有位置和顏色資料。兩者都以 float32x4 格式格式化(對映到 WGSL vec4<f32> 型別),並且顏色資料從每個頂點中偏移 16 位元組處開始。arrayStride 指定步幅,即構成每個頂點的位元組數,stepMode 指定資料應按頂點獲取。
const vertexBuffers = [
{
attributes: [
{
shaderLocation: 0, // position
offset: 0,
format: "float32x4",
},
{
shaderLocation: 1, // color
offset: 16,
format: "float32x4",
},
],
arrayStride: 32,
stepMode: "vertex",
},
];
接下來,我們建立一個描述符物件,該物件指定渲染管線階段的配置。對於兩個著色器階段,我們指定可以在其中找到相關程式碼的 GPUShaderModule(shaderModule),以及作為每個階段入口點的函式名稱。
此外,在頂點著色器階段,我們提供 vertexBuffers 物件來提供頂點資料的預期狀態。在片段著色器階段,我們提供一個顏色目標狀態陣列,指示指定的渲染格式(這與我們之前畫布上下文配置中指定的格式匹配)。
我們還指定了一個 primitive 物件,在這種情況下,它只是說明我們將要繪製的基本體的型別,以及一個 auto 的 layout。layout 屬性定義了在管線執行期間使用的所有 GPU 資源(緩衝區、紋理等)的佈局(結構、目的和型別)。在更復雜的應用程式中,這將採用 GPUPipelineLayout 物件的樣式,使用 GPUDevice.createPipelineLayout() 建立(您可以在我們的基本計算管線中看到一個示例),這允許 GPU 提前找出最有效地執行管線的方式。然而,我們指定了 auto 值,這將導致管線根據著色器程式碼中定義的任何繫結生成一個隱式繫結組佈局。
const pipelineDescriptor = {
vertex: {
module: shaderModule,
entryPoint: "vertex_main",
buffers: vertexBuffers,
},
fragment: {
module: shaderModule,
entryPoint: "fragment_main",
targets: [
{
format: navigator.gpu.getPreferredCanvasFormat(),
},
],
},
primitive: {
topology: "triangle-list",
},
layout: "auto",
};
最後,我們可以基於我們的 pipelineDescriptor 物件建立一個 GPURenderPipeline,透過將其作為引數傳遞給 GPUDevice.createRenderPipeline() 方法呼叫。
const renderPipeline = device.createRenderPipeline(pipelineDescriptor);
執行渲染通道
現在所有設定都已完成,我們可以實際執行渲染通道並在我們的 <canvas> 上繪製一些東西。要編碼任何稍後要發給 GPU 的命令,您需要建立一個 GPUCommandEncoder 例項,這可以透過呼叫 GPUDevice.createCommandEncoder() 來完成。
const commandEncoder = device.createCommandEncoder();
接下來,我們透過呼叫 GPUCommandEncoder.beginRenderPass() 建立一個 GPURenderPassEncoder 例項來啟動渲染通道。此方法將一個描述符物件作為引數,其中唯一強制的屬性是一個 colorAttachments 陣列。在這種情況下,我們指定
- 一個要渲染到的紋理檢視;我們透過
context.getCurrentTexture().createView()從<canvas>建立一個新檢視。 - 一旦載入並在任何繪圖發生之前,該檢視應“清除”為指定的顏色。這就是導致三角形後面出現藍色背景的原因。
- 當前渲染通道的值應為此顏色附件儲存。
const clearColor = { r: 0.0, g: 0.5, b: 1.0, a: 1.0 };
const renderPassDescriptor = {
colorAttachments: [
{
clearValue: clearColor,
loadOp: "clear",
storeOp: "store",
view: context.getCurrentTexture().createView(),
},
],
};
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
現在我們可以呼叫渲染通道編碼器的方法來繪製我們的三角形
- 呼叫
GPURenderPassEncoder.setPipeline()並將我們的renderPipeline物件作為引數,以指定用於渲染通道的管線。 - 呼叫
GPURenderPassEncoder.setVertexBuffer()並將我們的vertexBuffer物件作為引數,作為傳遞給管線進行渲染的資料來源。第一個引數是設定頂點緩衝區的槽位,它指向描述此緩衝區佈局的vertexBuffers陣列中元素的索引。 GPURenderPassEncoder.draw()啟動繪圖。我們的vertexBuffer中有三個頂點的資料,因此我們將頂點計數設定為3以繪製所有頂點。
passEncoder.setPipeline(renderPipeline);
passEncoder.setVertexBuffer(0, vertexBuffer);
passEncoder.draw(3);
為了完成命令序列的編碼並將其釋出到 GPU,還需要三個步驟。
- 我們呼叫
GPURenderPassEncoder.end()方法以表示渲染通道命令列表的結束。 - 我們呼叫
GPUCommandEncoder.finish()方法來完成已發出命令序列的記錄,並將其封裝到GPUCommandBuffer物件例項中。 - 我們將
GPUCommandBuffer提交到裝置的命令佇列(由GPUQueue例項表示),以便傳送到 GPU。裝置的佇列可透過GPUDevice.queue屬性獲得,並且可以透過呼叫GPUQueue.submit()將GPUCommandBuffer例項陣列新增到佇列中。
這三個步驟可以透過以下兩行程式碼實現
passEncoder.end();
device.queue.submit([commandEncoder.finish()]);
基本計算管線
在我們的基本計算演示中,我們讓 GPU 計算一些值,將它們儲存在輸出緩衝區中,將資料複製到暫存緩衝區,然後對映該暫存緩衝區,以便可以將資料讀取到 JavaScript 並記錄到控制檯。
該應用程式遵循與基本渲染演示類似的結構。我們以與之前相同的方式建立 GPUDevice 引用,並透過呼叫 GPUDevice.createShaderModule() 將著色器程式碼封裝到 GPUShaderModule 中。這裡的區別在於我們的著色器程式碼只有一個著色器階段,一個 @compute 階段
// Define global buffer size
const NUM_ELEMENTS = 1000;
const BUFFER_SIZE = NUM_ELEMENTS * 4; // Buffer size, in bytes
const shader = `
@group(0) @binding(0)
var<storage, read_write> output: array<f32>;
@compute @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id : vec3u,
@builtin(local_invocation_id)
local_id : vec3u,
) {
// Avoid accessing the buffer out of bounds
if (global_id.x >= ${NUM_ELEMENTS}) {
return;
}
output[global_id.x] =
f32(global_id.x) * 1000. + f32(local_id.x);
}
`;
建立緩衝區來處理我們的資料
在此示例中,我們建立了兩個 GPUBuffer 例項來處理我們的資料,一個 output 緩衝區用於高速寫入 GPU 計算結果,以及一個 stagingBuffer,我們將 output 的內容複製到其中,該緩衝區可以對映以允許 JavaScript 訪問這些值。
output被指定為儲存緩衝區,它將是複製操作的源。stagingBuffer被指定為可以對映以供 JavaScript 讀取的緩衝區,並且將是複製操作的目標。
const output = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
});
const stagingBuffer = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST,
});
建立繫結組佈局
建立管線時,我們指定要用於管線的繫結組。這首先涉及建立一個 GPUBindGroupLayout(透過呼叫 GPUDevice.createBindGroupLayout()),該佈局定義了將在此管線中使用的 GPU 資源(例如緩衝區)的結構和目的。此佈局用作繫結組遵循的模板。在此示例中,我們授予管線對單個記憶體緩衝區的訪問許可權,該緩衝區繫結到繫結槽 0(這與著色器程式碼中的相關繫結號 @binding(0) 匹配),可在管線的計算階段使用,並且緩衝區的目的定義為 storage。
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage",
},
},
],
});
接下來,我們透過呼叫 GPUDevice.createBindGroup() 建立一個 GPUBindGroup。我們向此方法呼叫傳遞一個描述符物件,該物件指定此繫結組所基於的繫結組佈局,以及要繫結到佈局中定義的槽位的變數的詳細資訊。在此示例中,我們宣告繫結 0,並指定應將我們之前定義的 output 緩衝區繫結到它。
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: output,
},
},
],
});
注意:您可以透過呼叫 GPUComputePipeline.getBindGroupLayout() 方法來檢索建立繫結組時要使用的隱式佈局。渲染管線也有一個版本:請參見 GPURenderPipeline.getBindGroupLayout()。
建立計算管線
有了以上所有內容,我們現在可以透過呼叫 GPUDevice.createComputePipeline() 並傳遞一個管線描述符物件來建立一個計算管線。這與建立渲染管線的方式類似。我們描述計算著色器,指定程式碼所在的模組和入口點。我們還為管線指定一個 layout,在這種情況下,透過呼叫 GPUDevice.createPipelineLayout() 基於我們之前定義的 bindGroupLayout 建立一個佈局。
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout],
}),
compute: {
module: shaderModule,
entryPoint: "main",
},
});
這裡與渲染管線佈局的一個區別是,我們沒有指定原始型別,因為我們沒有繪製任何東西。
執行計算通道
執行計算通道的結構與執行渲染通道相似,但有一些不同的命令。首先,使用 GPUCommandEncoder.beginComputePass() 建立通道編碼器。
在發出命令時,我們像以前一樣使用 GPUComputePassEncoder.setPipeline() 指定要使用的管線。然後,我們使用 GPUComputePassEncoder.setBindGroup() 指定我們要使用 bindGroup 來指定計算中使用的資料,並使用 GPUComputePassEncoder.dispatchWorkgroups() 指定用於執行計算的 GPU 工作組數量。
然後,我們使用 GPURenderPassEncoder.end() 訊號表示渲染通道命令列表的結束。
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
passEncoder.dispatchWorkgroups(Math.ceil(NUM_ELEMENTS / 64));
passEncoder.end();
將結果讀回 JavaScript
在將編碼的命令提交到 GPU 執行之前,我們使用 GPUCommandEncoder.copyBufferToBuffer() 將 output 緩衝區的內容複製到 stagingBuffer 緩衝區。
// Copy output buffer to staging buffer
commandEncoder.copyBufferToBuffer(
output,
0, // Source offset
stagingBuffer,
0, // Destination offset
BUFFER_SIZE, // Length, in bytes
);
// End frame by passing array of command buffers to command queue for execution
device.queue.submit([commandEncoder.finish()]);
一旦輸出資料在 stagingBuffer 中可用,我們使用 GPUBuffer.mapAsync() 方法將資料對映到中間記憶體,使用 GPUBuffer.getMappedRange() 獲取對映範圍的引用,將資料複製到 JavaScript,然後將其記錄到控制檯。我們還在使用完 stagingBuffer 後將其解除對映。
// map staging buffer to read results back to JS
await stagingBuffer.mapAsync(
GPUMapMode.READ,
0, // Offset
BUFFER_SIZE, // Length, in bytes
);
const copyArrayBuffer = stagingBuffer.getMappedRange(0, BUFFER_SIZE);
const data = copyArrayBuffer.slice();
stagingBuffer.unmap();
console.log(new Float32Array(data));
GPU 錯誤處理
WebGPU 呼叫在 GPU 程序中非同步驗證。如果發現錯誤,問題呼叫在 GPU 端被標記為無效。如果又進行了依賴於無效呼叫返回值的呼叫,則該物件也將被標記為無效,依此類推。因此,WebGPU 中的錯誤被稱為“傳染性”錯誤。
每個 GPUDevice 例項都維護自己的錯誤範圍堆疊。此堆疊最初是空的,但您可以透過呼叫 GPUDevice.pushErrorScope() 來將錯誤範圍推送到堆疊以捕獲特定型別的錯誤。
捕獲錯誤完成後,可以透過呼叫 GPUDevice.popErrorScope() 結束捕獲。這會將範圍從堆疊中彈出,並返回一個 Promise,該 Promise 解析為一個物件(GPUInternalError、GPUOutOfMemoryError 或 GPUValidationError)描述範圍內捕獲的第一個錯誤,如果未捕獲到錯誤,則返回 null。
我們已嘗試在適當的“驗證”部分中提供有用的資訊,以幫助您瞭解 WebGPU 程式碼中發生錯誤的原因,其中列出了避免錯誤的條件。例如,請參見 GPUDevice.createBindGroup() 驗證部分。其中一些資訊很複雜;我們決定不重複規範,而是隻列出以下錯誤條件:
- 不明顯,例如導致驗證錯誤的描述符屬性組合。沒有必要告訴您確保使用正確的描述符物件結構。這既明顯又模糊。
- 由開發者控制。某些錯誤條件純粹基於內部實現,與 Web 開發者無關。
您可以在直譯器中找到有關 WebGPU 錯誤處理的更多資訊——請參見 物件有效性和銷燬狀態 和 錯誤。WebGPU 錯誤處理最佳實踐提供了有用的實際示例和建議。
注意:WebGL 中處理錯誤的歷史方式是提供 getError() 方法來返回錯誤資訊。這存在問題,因為它同步返回錯誤,這不利於效能——每次呼叫都需要往返 GPU,並且需要完成所有先前發出的操作。它的狀態模型也是扁平的,這意味著錯誤可能會在不相關的程式碼之間洩露。WebGPU 的建立者決心改進這一點。
介面
API 入口點
-
API 的入口點——返回當前上下文的
GPU物件。 GPU-
使用 WebGPU 的起點。它可用於返回
GPUAdapter。 GPUAdapter-
表示一個 GPU 介面卡。您可以從中請求
GPUDevice、介面卡資訊、功能和限制。 GPUAdapterInfo-
包含有關介面卡的識別資訊。
配置 GPUDevice
GPUDevice-
表示一個邏輯 GPU 裝置。這是訪問大多數 WebGPU 功能的主要介面。
GPUSupportedFeatures-
一個 類似集合 的物件,描述了
GPUAdapter或GPUDevice支援的附加功能。 GPUSupportedLimits-
描述
GPUAdapter或GPUDevice支援的限制。
配置渲染 <canvas>
HTMLCanvasElement.getContext()—"webgpu"contextType-
呼叫
getContext()並傳入"webgpu"contextType會返回一個GPUCanvasContext物件例項,然後可以使用GPUCanvasContext.configure()對其進行配置。 GPUCanvasContext-
表示
<canvas>元素的 WebGPU 渲染上下文。
表示管線資源
GPUBuffer-
表示一塊記憶體,可用於儲存在 GPU 操作中使用的原始資料。
GPUExternalTexture-
一個包裝物件,包含
HTMLVideoElement快照,可用作 GPU 渲染操作中的紋理。 GPUSampler-
控制著色器如何轉換和過濾紋理資源資料。
GPUShaderModule-
對內部著色器模組物件的引用,一個 WGSL 著色器程式碼的容器,可以提交給 GPU 進行管線執行。
GPUTexture-
用於儲存一維、二維或三維資料陣列(例如影像)的容器,用於 GPU 渲染操作。
GPUTextureView-
對特定
GPUTexture定義的紋理子資源子集的一個檢視。
表示管線
GPUBindGroup-
基於
GPUBindGroupLayout,GPUBindGroup定義了一組要繫結在一起的資源以及這些資源在著色器階段中的使用方式。 GPUBindGroupLayout-
定義了管線中將使用的相關 GPU 資源(如緩衝區)的結構和目的,並用作建立
GPUBindGroup的模板。 GPUComputePipeline-
控制計算著色器階段,可在
GPUComputePassEncoder中使用。 GPUPipelineLayout-
定義了管線使用的
GPUBindGroupLayout。在命令編碼期間與管線一起使用的GPUBindGroup必須具有相容的GPUBindGroupLayout。 GPURenderPipeline-
控制頂點和片段著色器階段,可在
GPURenderPassEncoder或GPURenderBundleEncoder中使用。
編碼並將命令提交給 GPU
GPUCommandBuffer-
表示已記錄的 GPU 命令列表,可提交到
GPUQueue執行。 GPUCommandEncoder-
表示命令編碼器,用於編碼要傳送到 GPU 的命令。
GPUComputePassEncoder-
編碼與控制計算著色器階段相關的命令,由
GPUComputePipeline發出。是GPUCommandEncoder整體編碼活動的一部分。 GPUQueue-
控制已編碼命令在 GPU 上的執行。
GPURenderBundle-
預先錄製命令束的容器(參見
GPURenderBundleEncoder)。 GPURenderBundleEncoder-
用於預錄製命令束。這些命令束可以透過
executeBundles()方法在GPURenderPassEncoder中重複使用,次數不限。 GPURenderPassEncoder-
編碼與控制頂點和片段著色器階段相關的命令,由
GPURenderPipeline發出。是GPUCommandEncoder整體編碼活動的一部分。
對渲染通道執行查詢
GPUQuerySet-
用於記錄通道查詢的結果,例如遮擋或時間戳查詢。
除錯錯誤
GPUCompilationInfo-
一個
GPUCompilationMessage物件陣列,由 GPU 著色器模組編譯器生成,用於幫助診斷著色器程式碼問題。 GPUCompilationMessage-
表示由 GPU 著色器模組編譯器生成的一條資訊、警告或錯誤訊息。
GPUDeviceLostInfo-
當
GPUDevice.lostPromise解析時返回,提供有關裝置丟失原因的資訊。 GPUError-
由
GPUDevice.popErrorScope和uncapturederror事件公開的錯誤的基礎介面。 GPUInternalError-
由
GPUDevice.popErrorScope和GPUDeviceuncapturederror事件公開的錯誤型別之一。表示操作因系統或實現特定原因失敗,即使所有驗證要求都已滿足。 GPUOutOfMemoryError-
由
GPUDevice.popErrorScope和GPUDeviceuncapturederror事件公開的錯誤型別之一。表示沒有足夠的可用記憶體來完成請求的操作。 GPUPipelineError-
描述管線故障。當
Promise由GPUDevice.createComputePipelineAsync()或GPUDevice.createRenderPipelineAsync()呼叫拒絕時接收到的值。 GPUUncapturedErrorEvent-
GPUDeviceuncapturederror事件的事件物件型別。 GPUValidationError-
由
GPUDevice.popErrorScope和GPUDeviceuncapturederror事件公開的錯誤型別之一。描述應用程式錯誤,表明操作未透過 WebGPU API 的驗證約束。
安全要求
整個 API 僅在 安全上下文 中可用。
示例
規範
| 規範 |
|---|
| WebGPU # gpu-interface |
瀏覽器相容性
載入中…