Web Audio API 背後的基本概念
本文解釋了 Web Audio API 功能背後的一些音訊理論,旨在幫助您在設計應用程式如何路由音訊時做出明智的決定。如果您還不是一名音響工程師,它將為您提供足夠的背景知識,讓您理解 Web Audio API 的工作原理。
音訊圖
Web Audio API 涉及在音訊上下文中處理音訊操作,並且被設計為允許模組化路由。每個音訊節點執行一個基本音訊操作,並與一個或多個其他音訊節點連結,以形成一個音訊路由圖。支援多種具有不同通道佈局的源,甚至可以在單個上下文中。這種模組化設計提供了靈活性,可以建立具有動態效果的複雜音訊功能。
音訊節點透過它們的輸入和輸出連線起來,形成一個鏈,這個鏈以一個或多個源開始,經過一個或多個節點,然後到達一個目的地(儘管如果您只想視覺化一些音訊資料,您不必提供目的地)。一個簡單、典型的 Web 音訊工作流程如下所示:
- 建立音訊上下文。
- 在上下文中建立音訊源(例如
<audio>、振盪器或流)。 - 建立音訊效果(例如混響、二階濾波器、聲像器或壓縮器節點)。
- 選擇音訊的最終目的地(例如使用者的電腦揚聲器)。
- 將源節點連線到零個或多個效果節點,然後連線到所選目的地。
注意:通道表示法是一個數值,例如 2.0 或 5.1,表示訊號中可用音訊通道的數量。第一個數字是訊號包含的全頻段音訊通道數量。小數點後的數字表示為低頻效果 (LFE) 輸出保留的通道數量;這些通常被稱為 低音炮。

每個輸入或輸出都由一個或多個音訊通道組成,它們共同代表特定的音訊佈局。支援任何離散通道結構,包括單聲道、立體聲、四聲道、5.1聲道等。
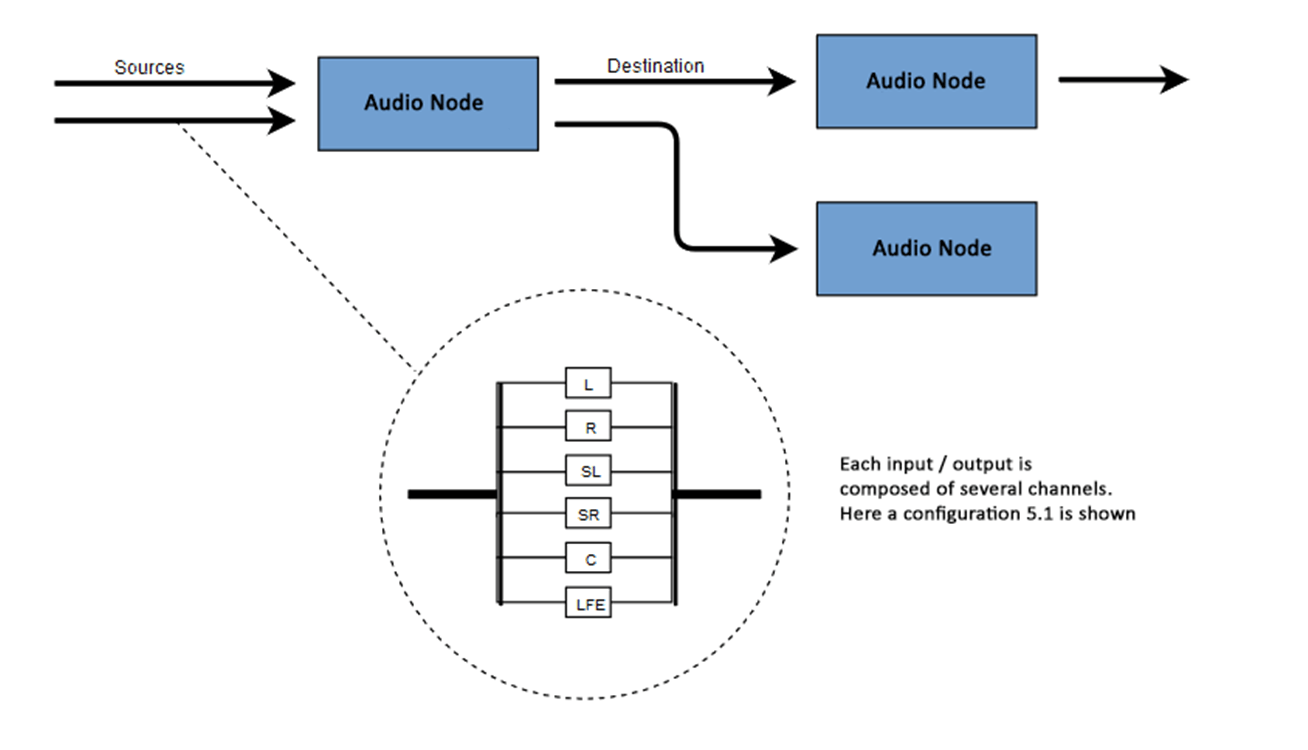
您有幾種獲取音訊的方式
- 聲音可以透過音訊節點(例如振盪器)直接在 JavaScript 中生成。
- 它可以從原始 PCM 資料建立(例如 .WAV 檔案或
decodeAudioData()支援的其他格式)。 - 它可以從 HTML 媒體元素生成,例如
<video>或<audio>。 - 它可以從 WebRTC
MediaStream獲取,例如網路攝像頭或麥克風。
音訊資料:樣本中的內容
當音訊訊號被處理時,會發生取樣。取樣是將連續訊號轉換為離散訊號的過程。換句話說,連續聲波(例如現場演奏的樂隊)被轉換為一系列數字樣本(離散時間訊號),這使得計算機能夠以離散塊處理音訊。
您可以在維基百科頁面 取樣(訊號處理) 上找到更多資訊。
音訊緩衝區:幀、樣本和通道
AudioBuffer 由三個引數定義
- 通道數(單聲道為 1,立體聲為 2 等),
- 其長度,即緩衝區內的取樣幀數,
- 以及取樣率,即每秒播放的取樣幀數。
一個樣本是一個 32 位浮點值,表示特定通道(如果是立體聲,則為左聲道或右聲道)中每個特定時間點的音訊流值。一個幀或取樣幀是所有通道在特定時間點播放的所有值的集合:所有通道在同一時間播放的所有樣本(立體聲為兩個,5.1 聲道為六個等)。
取樣率是這些樣本(或幀,因為一幀中的所有樣本同時播放)在一秒鐘內播放的數量,以赫茲 (Hz) 為單位測量。取樣率越高,音質越好。
我們來看一個單聲道和立體聲音訊緩衝區,每個都長一秒,取樣率為 44100Hz
- 單聲道緩衝區將有 44,100 個樣本和 44,100 個幀。
length屬性將為 44,100。 - 立體聲緩衝區將有 88,200 個樣本,但仍有 44,100 個幀。
length屬性仍為 44100,因為它等於幀數。

當緩衝區播放時,您將首先聽到最左邊的取樣幀,然後是緊鄰它的幀,然後是下一個,依此類推,直到緩衝區結束。在立體聲情況下,您將同時聽到兩個通道。取樣幀很方便,因為它們獨立於通道數,並以理想的方式表示時間,適用於精確的音訊操作。
注意:要從幀數獲取秒數,請將幀數除以取樣率。要從樣本數獲取幀數,您只需將後者除以通道數。
這裡有幾個簡單的例子
const context = new AudioContext();
const buffer = new AudioBuffer(context, {
numberOfChannels: 2,
length: 22050,
sampleRate: 44100,
});
注意:在數字音訊中,44,100 Hz(或表示為44.1 kHz)是一種常見的取樣頻率。為什麼是 44.1 kHz?
首先,因為人耳的聽力範圍大致在 20 Hz 到 20,000 Hz 之間。根據奈奎斯特-夏農取樣定理,取樣頻率必須大於要重現的最大頻率的兩倍。因此,取樣率必須大於 40,000 Hz。
其次,在取樣之前必須對訊號進行低通濾波,否則會發生混疊。雖然理想的低通濾波器可以完美地透過 20 kHz 以下的頻率(不衰減它們)並完美地截止 20 kHz 以上的頻率,但在實踐中,需要一個過渡帶,其中頻率部分衰減。過渡帶越寬,製作抗混疊濾波器就越容易和經濟。44.1 kHz 的取樣頻率允許 2.05 kHz 的過渡帶。
如果您使用上述呼叫,您將獲得一個雙聲道立體聲緩衝區,當在以 44100 Hz 執行的 AudioContext(非常常見,大多數普通音效卡都以該速率執行)上播放時,它將持續 0.5 秒:22,050 幀/44,100 Hz = 0.5 秒。
const context = new AudioContext();
const buffer = new AudioBuffer(context, {
numberOfChannels: 1,
length: 22050,
sampleRate: 22050,
});
如果您使用此呼叫,您將獲得一個單聲道緩衝區(單通道緩衝區),當在以 44,100 Hz 執行的 AudioContext 上播放時,它將自動重新取樣到 44,100 Hz(因此產生 44,100 幀),並持續 1.0 秒:44,100 幀/44,100 Hz = 1 秒。
注意:音訊重取樣與影像大小調整非常相似。假設您有一張 16 x 16 的影像,但想讓它填充 32 x 32 的區域。您對其進行大小調整(或重取樣)。結果質量較低(根據大小調整演算法,它可能會模糊或邊緣化),但它有效,調整大小後的影像佔用空間更少。重取樣音訊也是如此:您節省了空間,但實際上,您無法正確再現高頻內容或高音。
平面式緩衝區與交錯式緩衝區
Web Audio API 使用平面式緩衝區格式。左右聲道儲存方式如下
LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR (for a buffer of 16 frames)
這種結構在音訊處理中非常普遍,使得獨立處理每個通道變得容易。
另一種方法是使用交錯式緩衝區格式
LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR (for a buffer of 16 frames)
這種格式在不進行太多處理的情況下儲存和播放音訊時很常見,例如:.WAV 檔案或解碼後的 MP3 流。
由於 Web Audio API 旨在用於處理,因此它只公開平面式緩衝區。它使用平面格式,但在將音訊傳送到音效卡進行播放時將其轉換為交錯格式。相反,當 API 解碼 MP3 時,它從交錯格式開始,並將其轉換為平面格式進行處理。
音訊通道
每個音訊緩衝區可能包含不同數量的通道。大多數現代音訊裝置使用基本的單聲道(只有一個通道)和立體聲(左聲道和右聲道)設定。一些更復雜的設定支援環繞聲設定(如四聲道和5.1聲道),這些設定由於其高通道數而可以帶來更豐富的音效體驗。我們通常使用下表中詳細的標準縮寫來表示通道
| 名稱 | 渠道 |
|---|---|
| 單聲道 | 0: M: 單聲道 |
| 立體聲 | 0: L: 左 1: R: 右 |
| 四聲道 | 0: L: 左 1: R: 右 2: SL: 左環繞 3: SR: 右環繞 |
| 5.1 | 0: L: 左 1: R: 右 2: C: 中置 3: LFE: 低音炮 4: SL: 左環繞 5: SR: 右環繞 |
上混和下混
當輸入和輸出的通道數不匹配時,必須進行上混或下混。以下規則透過將 AudioNode.channelInterpretation 屬性設定為 speakers 或 discrete 來控制
| 解釋 | 輸入通道 | 輸出通道 | 混合規則 |
|---|---|---|---|
揚聲器 |
1 (單聲道) |
2 (立體聲) |
從單聲道上混到立體聲.M 輸入通道用於兩個輸出通道(L 和 R)。output.L = input.M
|
1 (單聲道) |
4 (四聲道) |
從單聲道上混到四聲道。M 輸入通道用於非環繞聲輸出通道(L 和 R)。環繞聲輸出通道(SL 和 SR)是靜音的。output.L = input.M
|
|
1 (單聲道) |
6 (5.1) |
從單聲道上混到 5.1 聲道。M 輸入通道用於中置輸出通道(C)。所有其他通道(L、R、LFE、SL 和 SR)是靜音的。output.L = 0output.C = input.M
|
|
2 (立體聲) |
1 (單聲道) |
從立體聲下混到單聲道. 兩個輸入通道( L 和 R)以相同比例組合,產生唯一的輸出通道(M)。output.M = 0.5 * (input.L + input.R)
|
|
2 (立體聲) |
4 (四聲道) |
從立體聲上混到四聲道。L 和 R 輸入通道用於各自的非環繞聲輸出通道(L 和 R)。環繞聲輸出通道(SL 和 SR)是靜音的。output.L = input.L
|
|
2 (立體聲) |
6 (5.1) |
從立體聲上混到 5.1 聲道。L 和 R 輸入通道用於各自的非環繞聲輸出通道(L 和 R)。環繞聲輸出通道(SL 和 SR),以及中置(C)和低音炮(LFE)通道,都保持靜音。output.L = input.L
|
|
4 (四聲道) |
1 (單聲道) |
從四聲道下混到單聲道. 所有四個輸入通道( L、R、SL 和 SR)以相同比例組合,產生唯一的輸出通道(M)。output.M = 0.25 * (input.L + input.R + input.SL + input.SR)
|
|
4 (四聲道) |
2 (立體聲) |
從四聲道下混到立體聲. 兩個左輸入通道( L 和 SL)以相同比例組合,產生唯一的左輸出通道(L)。同樣,兩個右輸入通道(R 和 SR)以相同比例組合,產生唯一的右輸出通道(R)。output.L = 0.5 * (input.L + input.SL)output.R = 0.5 * (input.R + input.SR)
|
|
4 (四聲道) |
6 (5.1) |
從四聲道上混到 5.1 聲道。L、R、SL 和 SR 輸入通道用於各自的輸出通道(L 和 R)。中置(C)和低音炮(LFE)通道保持靜音。output.L = input.Loutput.R = input.Routput.C = 0output.LFE = 0output.SL = input.SLoutput.SR = input.SR
|
|
6 (5.1) |
1 (單聲道) |
從 5.1 聲道下混到單聲道。 左聲道( L 和 SL)、右聲道(R 和 SR)和中置聲道都混合在一起。環繞聲道略微衰減,常規側聲道透過乘以 √2/2 進行功率補償,使其算作單個聲道。低音炮(LFE)聲道丟失。output.M = 0.7071 * (input.L + input.R) + input.C + 0.5 * (input.SL + input.SR)
|
|
6 (5.1) |
2 (立體聲) |
從 5.1 聲道下混到立體聲。 中置聲道( C)與每個側環繞聲道(SL 或 SR)相加,並混合到每個側聲道。由於它被下混到兩個聲道,因此以較低的功率混合:在每種情況下,它都乘以 √2/2。低音炮(LFE)聲道丟失。output.L = input.L + 0.7071 * (input.C + input.SL)output.R = input.R + 0.7071 * (input.C + input.SR)
|
|
6 (5.1) |
4 (四聲道) |
從 5.1 聲道下混到四聲道。 中置( C)與側面非環繞聲道(L 和 R)混合。由於它被下混到兩個聲道,因此以較低的功率混合:在每種情況下,它都乘以 √2/2。環繞聲道保持不變。低音炮(LFE)聲道丟失。output.L = input.L + 0.7071 * input.Coutput.R = input.R + 0.7071 * input.Coutput.SL = input.SLoutput.SR = input.SR
|
|
| 其他非標準佈局 | 非標準通道佈局的行為與將 channelInterpretation 設定為 discrete 時的行為相同。規範明確允許未來定義新的揚聲器佈局。因此,這種回退不是面向未來的,因為瀏覽器對特定通道數的行為在未來可能會改變。 |
||
離散 |
任意 (x) |
任意 (y),其中 x<y |
上混離散通道。 用其對應的輸入通道填充每個輸出通道 — 即,具有相同索引的輸入通道。沒有對應輸入通道的通道保持靜音。 |
任意 (x) |
任意 (y),其中 x>y |
下混離散通道。 用其對應的輸入通道填充每個輸出通道 — 即,具有相同索引的輸入通道。沒有對應輸出通道的輸入通道將被丟棄。 |
|
視覺化
通常,我們隨時間獲取輸出以生成音訊視覺化,通常讀取其增益或頻率資料。然後,使用圖形工具,我們將獲得的資料轉換為視覺表示,例如圖形。Web Audio API 提供了一個 AnalyserNode,它不會改變透過它的音訊訊號。此外,它會輸出音訊資料,允許我們透過諸如 <canvas> 等技術對其進行處理。

您可以使用以下方法獲取資料
AnalyserNode.getFloatFrequencyData()-
將當前頻率資料複製到傳入的
Float32Array陣列中。 AnalyserNode.getByteFrequencyData()-
將當前頻率資料複製到傳入的
Uint8Array(無符號位元組陣列)中。 AnalyserNode.getFloatTimeDomainData()-
將當前波形或時域資料複製到傳入的
Float32Array陣列中。 AnalyserNode.getByteTimeDomainData()-
將當前波形或時域資料複製到傳入的
Uint8Array(無符號位元組陣列)中。
注意:有關更多資訊,請參閱我們的使用 Web Audio API 進行視覺化文章。
空間化
音訊空間化允許我們模擬音訊訊號在物理空間中某個點的位置和行為,模擬聽眾聽到該音訊。在 Web Audio API 中,空間化由 PannerNode 和 AudioListener 處理。
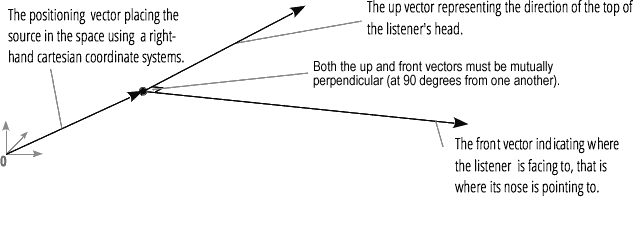
聲像器使用右手笛卡爾座標系來描述音訊源的位置作為向量,以及其方向作為 3D 方向錐。錐體可以非常大,例如,對於全向聲源。

同樣,Web Audio API 使用右手笛卡爾座標系描述聽眾:其位置作為向量,其方向作為兩個方向向量,向上和向前。這些向量定義了聽眾頭頂的方向和聽眾鼻子指向的方向。這些向量相互垂直。
注意:有關更多資訊,請參閱我們的Web 音訊空間化基礎文章。
扇入和扇出
在音訊術語中,扇入描述了 ChannelMergerNode 接收一系列單聲道輸入源並輸出單個多通道訊號的過程

扇出描述了相反的過程,即 ChannelSplitterNode 接收多通道輸入源並輸出多個單聲道輸出訊號
