JavaScript 型別化陣列
JavaScript 型別化陣列是類陣列物件,它提供了一種在記憶體緩衝區中讀寫原始二進位制資料的機制。
型別化陣列不旨在取代任何功能的常規陣列。相反,它們為開發人員提供了一個熟悉的介面來操作二進位制資料。這在與平臺功能互動時非常有用,例如音訊和影片操作、使用 WebSockets 訪問原始資料等等。JavaScript 型別化陣列中的每個條目都是一個原始二進位制值,其格式支援多種,從 8 位整數到 64 位浮點數。
型別化陣列物件與具有相似語義的陣列共享許多相同的方法。但是,型別化陣列**不應**與普通陣列混淆,因為對型別化陣列呼叫 Array.isArray() 會返回 false。此外,並非所有適用於普通陣列的方法都受型別化陣列支援(例如,push 和 pop)。
為了實現最大的靈活性和效率,JavaScript 型別化陣列將實現分為**緩衝區**和**檢視**。緩衝區是表示資料塊的物件;它沒有可言說的格式,也無法訪問其內容。為了訪問緩衝區中包含的記憶體,您需要使用檢視。檢視提供了一個**上下文**——即資料型別、起始偏移量和元素數量。
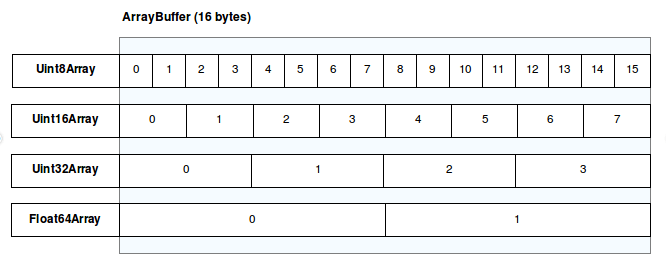
緩衝區
有兩種型別的緩衝區:ArrayBuffer 和 SharedArrayBuffer。兩者都是記憶體跨度的低階表示。它們的名稱中帶有“陣列”,但它們與陣列沒有太多關係——您無法直接讀寫它們。相反,緩衝區是隻包含原始資料的通用物件。為了訪問緩衝區表示的記憶體,您需要使用檢視。
緩衝區支援以下操作
- **分配**:一旦建立了新緩衝區,就會分配新的記憶體跨度並將其初始化為
0。 - **複製**:使用
slice()方法,您可以高效地複製記憶體的一部分,而無需建立檢視來手動複製每個位元組。 - **傳輸**:使用
transfer()和transferToFixedLength()方法,您可以將記憶體跨度的所有權傳輸到新的緩衝區物件。這在不同執行上下文之間傳輸資料而無需複製時非常有用。傳輸後,原始緩衝區不再可用。SharedArrayBuffer無法傳輸(因為緩衝區已被所有執行上下文共享)。 - **調整大小**:使用
resize()方法,您可以調整記憶體跨度的大小(要麼請求更多記憶體空間,只要不超過預設的maxByteLength限制,要麼釋放一些記憶體空間)。SharedArrayBuffer只能增長,不能縮小。
ArrayBuffer 和 SharedArrayBuffer 之間的區別在於,前者一次只能由一個執行上下文擁有。如果您將 ArrayBuffer 傳遞給不同的執行上下文,它將被**傳輸**,並且原始 ArrayBuffer 將變得不可用。這確保了在任何給定時間只有一個執行上下文可以訪問記憶體。SharedArrayBuffer 在傳遞給不同的執行上下文時不會被傳輸,因此它可以同時被多個執行上下文訪問。這可能會在多個執行緒訪問同一記憶體跨度時引入競態條件,因此 Atomics 方法等操作變得有用。
檢視
目前主要有兩種檢視:型別化陣列檢視和 DataView。型別化陣列提供了實用方法,允許您方便地轉換二進位制資料。DataView 更低階,允許對資料訪問進行精細控制。使用這兩種檢視讀寫資料的方式非常不同。
這兩種檢視都會使 ArrayBuffer.isView() 返回 true。它們都具有以下屬性
buffer-
檢視引用的底層緩衝區。
byteOffset-
檢視從其緩衝區起始位置開始的偏移量(以位元組為單位)。
byteLength-
檢視的長度(以位元組為單位)。
兩個建構函式都接受上述三個作為單獨的引數,儘管型別化陣列建構函式接受 length 作為元素數量而不是位元組數量。
型別化陣列檢視
型別化陣列檢視具有自描述性名稱,併為所有常見的數字型別(如 Int8、Uint32、Float64 等)提供檢視。有一種特殊的型別化陣列檢視,Uint8ClampedArray,它將值限制在 0 到 255 之間。這對於 Canvas 資料處理非常有用,例如。
| 型別 | 值範圍 | 位元組大小 | Web IDL 型別 |
|---|---|---|---|
Int8Array |
-128 到 127 | 1 | byte |
Uint8Array |
0 到 255 | 1 | octet |
Uint8ClampedArray |
0 到 255 | 1 | octet |
Int16Array |
-32768 到 32767 | 2 | short |
Uint16Array |
0 到 65535 | 2 | unsigned short |
Int32Array |
-2147483648 到 2147483647 | 4 | long |
Uint32Array |
0 到 4294967295 | 4 | unsigned long |
Float16Array |
-65504 到 65504 |
2 | N/A |
Float32Array |
-3.4e38 到 3.4e38 |
4 | unrestricted float |
Float64Array |
-1.8e308 到 1.8e308 |
8 | unrestricted double |
BigInt64Array |
-263 到 263 - 1 | 8 | bigint |
BigUint64Array |
0 到 264 - 1 | 8 | bigint |
所有型別化陣列檢視都具有相同的由 TypedArray 類定義的方法和屬性。它們僅在底層資料型別和位元組大小上有所不同。這在值編碼和規範化中進行了更詳細的討論。
型別化陣列原則上是定長的,因此可能改變陣列長度的陣列方法不可用。這包括 pop、push、shift、splice 和 unshift。此外,flat 不可用,因為沒有巢狀的型別化陣列,並且包括 concat 和 flatMap 在內的相關方法沒有很好的用例,因此不可用。由於 splice 不可用,toSpliced 也不可用。所有其他陣列方法在 Array 和 TypedArray 之間共享。
另一方面,TypedArray 具有額外的 set 和 subarray 方法,可最佳化處理檢視同一緩衝區的多個型別化陣列。set() 方法允許使用來自另一個數組或型別化陣列的資料一次設定多個型別化陣列索引。如果兩個型別化陣列共享相同的底層緩衝區,則操作可能更高效,因為它是一個快速的記憶體移動。subarray() 方法建立一個新的型別化陣列檢視,該檢視引用與原始型別化陣列相同的緩衝區,但跨度更窄。
無法在不更改底層緩衝區的情況下直接更改型別化陣列的長度。但是,當型別化陣列檢視可調整大小的緩衝區並且沒有固定的 byteLength 時,它是**長度跟蹤**的,並且會隨著可調整大小的緩衝區調整大小而自動調整以適應底層緩衝區。有關詳細資訊,請參閱檢視可調整大小緩衝區時的行為。
與常規陣列類似,您可以使用方括號表示法訪問型別化陣列元素。檢索底層緩衝區中相應的位元組並將其解釋為數字。任何使用數字(或數字的字串表示,因為在訪問屬性時數字總是轉換為字串)的屬性訪問都將由型別化陣列代理——它們從不與物件本身互動。這意味著,例如
- 越界索引訪問總是返回
undefined,而不會實際訪問物件上的屬性。 - 任何嘗試寫入此類越界屬性的操作都沒有效果:它不會丟擲錯誤,也不會更改緩衝區或型別化陣列。
- 型別化陣列索引似乎是可配置和可寫入的,但任何嘗試更改其屬性的操作都將失敗。
const uint8 = new Uint8Array([1, 2, 3]);
console.log(uint8[0]); // 1
// For illustrative purposes only. Not for production code.
uint8[-1] = 0;
uint8[2.5] = 0;
uint8[NaN] = 0;
console.log(Object.keys(uint8)); // ["0", "1", "2"]
console.log(uint8[NaN]); // undefined
// Non-numeric access still works
uint8[true] = 0;
console.log(uint8[true]); // 0
Object.freeze(uint8); // TypeError: Cannot freeze array buffer views with elements
DataView
DataView 是一個低階介面,提供 getter/setter API 來讀取和寫入緩衝區中的任意資料。這在處理不同型別的資料時非常有用。型別化陣列檢視是您平臺的本機位元組順序(參見位元組序)。使用 DataView,可以控制位元組順序。預設情況下,它是大端位元組序——位元組從最高有效位到最低有效位排序。可以使用 getter/setter 方法反轉此順序,使位元組從最低有效位到最高有效位排序(小端位元組序)。
DataView 不需要對齊;多位元組讀寫可以從任何指定的偏移量開始。setter 方法以相同的方式工作。
以下示例使用 DataView 獲取任何數字的二進位制表示
function toBinary(
x,
{ type = "Float64", littleEndian = false, separator = " ", radix = 16 } = {},
) {
const bytesNeeded = globalThis[`${type}Array`].BYTES_PER_ELEMENT;
const dv = new DataView(new ArrayBuffer(bytesNeeded));
dv[`set${type}`](0, x, littleEndian);
const bytes = Array.from({ length: bytesNeeded }, (_, i) =>
dv
.getUint8(i)
.toString(radix)
.padStart(8 / Math.log2(radix), "0"),
);
return bytes.join(separator);
}
console.log(toBinary(1.1)); // 3f f1 99 99 99 99 99 9a
console.log(toBinary(1.1, { littleEndian: true })); // 9a 99 99 99 99 99 f1 3f
console.log(toBinary(20, { type: "Int8", radix: 2 })); // 00010100
使用型別化陣列的 Web API
這些是一些使用型別化陣列的 API 示例;還有其他,並且一直在新增。
FileReader.prototype.readAsArrayBuffer()-
FileReader.prototype.readAsArrayBuffer()方法開始讀取指定Blob或File的內容。 fetch()-
fetch()的body選項可以是型別化陣列或ArrayBuffer,使您能夠將這些物件作為POST請求的有效負載傳送。 ImageData.data-
是一個
Uint8ClampedArray,表示一個包含 RGBA 順序資料的二維陣列,整數值在0到255之間(包括)。
示例
將檢視與緩衝區一起使用
首先,我們需要建立一個緩衝區,這裡固定長度為 16 位元組
const buffer = new ArrayBuffer(16);
此時,我們有一個所有位元組都預初始化為 0 的記憶體塊。但是,我們能做的並不多。例如,我們可以確認緩衝區的大小是否正確
if (buffer.byteLength === 16) {
console.log("Yes, it's 16 bytes.");
} else {
console.log("Oh no, it's the wrong size!");
}
在我們真正使用這個緩衝區之前,我們需要建立一個檢視。讓我們建立一個將緩衝區中的資料視為 32 位有符號整數陣列的檢視
const int32View = new Int32Array(buffer);
現在我們可以像普通陣列一樣訪問陣列中的欄位
for (let i = 0; i < int32View.length; i++) {
int32View[i] = i * 2;
}
這用值 0、2、4 和 6 填充了陣列中的 4 個條目(4 個條目,每個 4 位元組,總共 16 位元組)。
同一資料的多個檢視
當您考慮可以在同一資料上建立多個檢視時,事情開始變得非常有趣。例如,給定上面的程式碼,我們可以像這樣繼續
const int16View = new Int16Array(buffer);
for (let i = 0; i < int16View.length; i++) {
console.log(`Entry ${i}: ${int16View[i]}`);
}
這裡我們建立一個 16 位整數檢視,它與現有的 32 位檢視共享相同的緩衝區,並將緩衝區中的所有值作為 16 位整數輸出。現在我們得到輸出 0、0、2、0、4、0、6、0(假設是小端編碼)
Int16Array | 0 | 0 | 2 | 0 | 4 | 0 | 6 | 0 | Int32Array | 0 | 2 | 4 | 6 | ArrayBuffer | 00 00 00 00 | 02 00 00 00 | 04 00 00 00 | 06 00 00 00 |
不過,您可以更進一步。考慮一下
int16View[0] = 32;
console.log(`Entry 0 in the 32-bit array is now ${int32View[0]}`);
輸出是 "32 位陣列中的條目 0 現在是 32"。
換句話說,這兩個陣列確實在同一個資料緩衝區上檢視,將其視為不同的格式。
Int16Array | 32 | 0 | 2 | 0 | 4 | 0 | 6 | 0 | Int32Array | 32 | 2 | 4 | 6 | ArrayBuffer | 20 00 00 00 | 02 00 00 00 | 04 00 00 00 | 06 00 00 00 |
您可以對任何檢視型別執行此操作,儘管如果您設定一個整數然後將其讀取為浮點數,您可能會得到一個奇怪的結果,因為位被解釋的方式不同。
const float32View = new Float32Array(buffer);
console.log(float32View[0]); // 4.484155085839415e-44
從緩衝區讀取文字
緩衝區不總是表示數字。例如,讀取檔案可以為您提供文字資料緩衝區。您可以使用型別化陣列從緩衝區中讀取此資料。
以下使用 TextDecoder Web API 讀取 UTF-8 文字
const buffer = new ArrayBuffer(8);
const uint8 = new Uint8Array(buffer);
// Data manually written here, but pretend it was already in the buffer
uint8.set([228, 189, 160, 229, 165, 189]);
const text = new TextDecoder().decode(uint8);
console.log(text); // "你好"
以下使用 String.fromCharCode() 方法讀取 UTF-16 文字
const buffer = new ArrayBuffer(8);
const uint16 = new Uint16Array(buffer);
// Data manually written here, but pretend it was already in the buffer
uint16.set([0x4f60, 0x597d]);
const text = String.fromCharCode(...uint16);
console.log(text); // "你好"
處理複雜資料結構
透過將單個緩衝區與多個不同型別的檢視結合起來,從緩衝區中不同的偏移量開始,您可以與包含多種資料型別的資料物件互動。這使您例如可以與 WebGL 或資料檔案中的複雜資料結構互動。
考慮這個 C 結構
struct someStruct {
unsigned long id;
char username[16];
float amountDue;
};
您可以像這樣訪問包含此格式資料的緩衝區
const buffer = new ArrayBuffer(24);
// … read the data into the buffer …
const idView = new Uint32Array(buffer, 0, 1);
const usernameView = new Uint8Array(buffer, 4, 16);
const amountDueView = new Float32Array(buffer, 20, 1);
然後您可以訪問,例如,使用 amountDueView[0] 訪問應付款。
**注意:** C 結構中的資料結構對齊是平臺相關的。請注意並考慮這些填充差異。
轉換為普通陣列
處理型別化陣列後,有時將其轉換回普通陣列以受益於 Array 原型很有用。這可以透過使用 Array.from() 來完成
const typedArray = new Uint8Array([1, 2, 3, 4]);
const normalArray = Array.from(typedArray);
以及展開語法
const typedArray = new Uint8Array([1, 2, 3, 4]);
const normalArray = [...typedArray];
另見
- 使用型別化陣列更快地操作 Canvas 畫素 (hacks.mozilla.org, 2011)
- 型別化陣列 - 瀏覽器中的二進位制資料 (web.dev, 2012)
- 位元組序
ArrayBufferDataViewTypedArraySharedArrayBuffer