HTML、CSS 和 DOM 如何處理空白字元
在DOM中存在空白字元可能會導致佈局問題,並以意想不到的方式使內容樹的操作變得困難,具體取決於其所在位置。本文探討了何時會出現困難,並介紹了可以採取哪些措施來緩解由此產生的問題。
什麼是空白字元?
空白字元是指僅由空格、製表符或換行符(確切地說是 CRLF 序列、回車符或換行符)組成的任何字串。這些字元允許您以易於自己和他人的閱讀方式格式化程式碼。事實上,我們的許多原始碼都充滿了這些空白字元,我們只傾向於在生產構建步驟中將其刪除以減少程式碼下載大小。
HTML 在很大程度上忽略空白字元?
在 HTML 的情況下,空白字元在很大程度上被忽略 - 詞語之間的空白字元被視為單個字元,元素開頭和結尾以及元素外部的空白字元會被忽略。請看以下最小示例
<!DOCTYPE html>
<h1> Hello World! </h1>
此原始碼在DOCTYPE之後包含幾個換行符,在<h1>元素之前、之後和內部包含大量空格字元,但瀏覽器似乎根本不在乎,只是顯示“Hello World!”,就像這些字元根本不存在一樣
這樣是為了防止空白字元影響頁面佈局。在元素周圍和內部建立空格是 CSS 的工作。
空白字元發生了什麼?
然而,它們並沒有消失。
原始文件中 HTML 元素外部的任何空白字元都將在 DOM 中表示。這是內部需要的,以便編輯器可以保留文件的格式。這意味著
- 將有一些文字節點僅包含空白字元,並且
- 一些文字節點將在開頭或結尾處有空白字元。
例如,請看以下文件
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>Paragraph</p>
</body>
</html>
此文件的 DOM 樹如下所示

在 DOM 中保留空白字元在很多方面都是有用的,但在某些情況下,這會使某些佈局更難實現,並給希望遍歷 DOM 中節點的開發人員帶來問題。我們將在後面介紹這些問題以及一些解決方案。
CSS 如何處理空白字元?
大多數空白字元都被忽略,但並非全部。在前面的示例中,“Hello”和“World!”之間的空格之一在瀏覽器中呈現頁面時仍然存在。瀏覽器引擎中有一些規則決定哪些空白字元是有用的,哪些不是 - 這些規則至少部分在CSS 文字模組級別 3中指定,特別是關於CSS white-space 屬性和空白字元處理細節的部分,但我們下面也提供了一個更簡單的解釋。
示例
讓我們再舉一個例子。為了方便起見,我們添加了一條註釋,其中所有空格用◦表示,所有制表符用⇥表示,所有換行符用⏎表示
此示例
<h1> Hello
<span> World!</span> </h1>
<!--
<h1>◦◦◦Hello◦⏎
⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>
-->
在瀏覽器中呈現如下
解釋
<h1>元素僅包含內聯元素。實際上,它包含
- 一個文字節點(包含一些空格、單詞“Hello”和一些製表符)。
- 一個內聯元素(
<span>,包含一個空格和單詞“World!”)。 - 另一個文字節點(僅包含製表符和空格)。
因此,它建立了所謂的內聯格式化上下文。這是瀏覽器引擎使用的可能的佈局渲染上下文之一。
在此上下文中,空白字元處理可以概括如下
- 首先,忽略換行符前後所有空格和製表符,因此,如果我們採用之前示例中的標記...並應用此第一條規則,我們得到html
<h1>◦◦◦Hello◦⏎ ⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>html<h1>◦◦◦Hello⏎ <span>◦World!</span>⇥◦◦</h1> - 接下來,所有制表符都將被視為空格字元,因此示例變為html
<h1>◦◦◦Hello⏎ <span>◦World!</span>◦◦◦</h1> - 接下來,換行符將轉換為空格html
<h1>◦◦◦Hello◦<span>◦World!</span>◦◦◦</h1> - 之後,忽略緊跟在另一個空格之後的任何空格(即使跨越兩個單獨的內聯元素),因此我們最終得到html
<h1>◦Hello◦<span>World!</span>◦</h1> - 最後,刪除元素開頭和結尾處的空格序列,因此我們最終得到html
<h1>Hello◦<span>World!</span></h1>
這就是為什麼訪問網頁的人會在頁面頂部看到“Hello World!”這個短語整齊地寫著,而不是一個奇怪地縮排的“Hello”後面跟著一個更奇怪地縮排的“World!”在下一行。
注意:Firefox 開發者工具從 52 版本開始支援突出顯示文字節點,這使得更容易準確地檢視空白字元包含在哪些節點中。純空白字元節點用“whitespace”標籤標記。
塊格式化上下文中的空白字元
上面我們只查看了包含內聯元素和內聯格式化上下文的元素。如果某個元素至少包含一個塊級元素,則它將建立所謂的塊格式化上下文。
在此上下文中,空白字元的處理方式大不相同。
示例
讓我們看一個例子來解釋一下。我們像之前一樣標記了空白字元。
我們有 3 個僅包含空白字元的文字節點,第一個 <div> 之前有一個,兩個 <div> 之間有一個,第二個 <div> 之後有一個。
<body>
<div> Hello </div>
<div> World! </div>
</body>
<!--
<body>⏎
⇥<div>◦◦Hello◦◦</div>⏎
⏎
◦◦◦<div>◦◦World!◦◦</div>◦◦⏎
</body>
-->
呈現如下
解釋
我們可以概括此處空白字元的處理方式如下(不同瀏覽器之間的確切行為可能存在一些細微差異,但這基本上有效)
- 因為我們在塊格式化上下文中,所以所有內容都必須是塊,因此我們的 3 個文字節點也變成塊,就像 2 個
<div>一樣。塊佔據可用的全部寬度,並彼此堆疊,這意味著,從上面的示例開始...我們最終得到由以下塊列表組成的佈局html<body>⏎ ⇥<div>◦◦Hello◦◦</div>⏎ ⏎ ◦◦◦<div>◦◦World!◦◦</div>◦◦⏎ </body>html<block>⏎⇥</block> <block>◦◦Hello◦◦</block> <block>⏎◦◦◦</block> <block>◦◦World!◦◦</block> <block>◦◦⏎</block> - 然後透過將內聯格式化上下文中空白字元的處理規則應用於這些塊,進一步簡化此佈局html
<block></block> <block>Hello</block> <block></block> <block>World!</block> <block></block> - 我們現在擁有的 3 個空塊不會在最終佈局中佔用任何空間,因為它們不包含任何內容,因此我們最終只會得到 2 個佔用頁面空間的塊。檢視網頁的人會看到“Hello”和“World!”分別在兩行上,正如您期望的 2 個
<div>的佈局一樣。瀏覽器引擎基本上忽略了原始碼中新增的所有空白字元。
內聯和內聯塊元素之間的空格
讓我們繼續探討由於空白字元可能出現的一些問題以及如何解決這些問題。首先,我們將瞭解內聯和內聯塊元素之間的空格會發生什麼。事實上,我們在第一個示例中已經看到了這一點,當時我們描述瞭如何在內聯格式化上下文中處理空白字元。
我們說有一些規則可以忽略大多數字符,但分隔單詞的字元會保留下來。當您只處理僅包含內聯元素(如 <em>、<strong>、<span> 等)的塊級元素(如 <p>)時,您通常不會關心這一點,因為最終進入佈局的額外空白字元有助於分隔句子中的單詞。
但是,當您開始使用 inline-block 元素時,情況會變得更有趣。這些元素在外部表現得像內聯元素,在內部表現得像塊元素,並且通常用於並排顯示比文字更復雜的 UI 部分,例如導航選單項。
由於它們是塊級元素,許多人期望它們的行為像塊級元素那樣,但實際上並非如此。如果相鄰的內聯元素之間存在格式化空白字元,這將在佈局中產生空格,就像文字中單詞之間的空格一樣。
示例
考慮以下示例(同樣,我們包含了一個 HTML 註釋,其中顯示了 HTML 中的空白字元)
.people-list {
list-style-type: none;
margin: 0;
padding: 0;
}
.people-list li {
display: inline-block;
width: 2em;
height: 2em;
background: #f06;
border: 1px solid;
}
<ul class="people-list">
<li></li>
<li></li>
<li></li>
<li></li>
<li></li>
</ul>
<!--
<ul class="people-list">⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
</ul>
-->
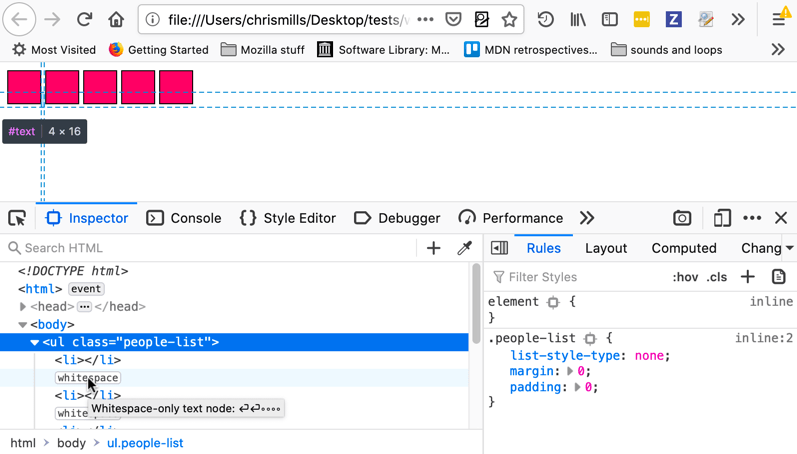
呈現效果如下
您可能不希望塊級元素之間出現間隙——根據用例(這是一個頭像列表還是水平導航按鈕?),您可能希望元素邊彼此緊貼,並能夠自己控制任何間距。
Firefox DevTools HTML 檢查器將突出顯示文字節點,並準確顯示元素佔據的區域——如果您想知道是什麼導致了問題,並且可能認為您在其中添加了一些額外的邊距或其他內容,這將非常有用!
解決方案
有一些方法可以解決此問題
使用 Flexbox 建立水平專案列表,而不是嘗試使用 inline-block 解決方案。這將為您處理所有內容,並且絕對是首選解決方案
ul {
list-style-type: none;
margin: 0;
padding: 0;
display: flex;
}
如果您需要依賴 inline-block,您可以將列表的 font-size 設定為 0。這僅在您的塊未使用 em(基於 font-size,因此塊大小最終也將為 0)進行大小調整時才有效。rems 將是這裡一個不錯的選擇
ul {
font-size: 0;
/* … */
}
li {
display: inline-block;
width: 2rem;
height: 2rem;
/* … */
}
或者,您可以在列表項上設定負邊距
li {
display: inline-block;
width: 2rem;
height: 2rem;
margin-right: -0.25rem;
}
您還可以透過將列表項全部放在原始碼中的同一行來解決此問題,這會導致不會在第一時間建立空白字元節點。
<li></li><li></li><li></li><li></li><li></li>
DOM 遍歷和空白字元
在嘗試使用 JavaScript 進行 DOM 操作時,您也可能會遇到由於空白字元節點導致的問題。例如,如果您有一個父節點的引用,並希望使用 Node.firstChild 影響其第一個元素子節點,如果在父標籤的開始標記之後有一個不相關的空白字元節點,則您將無法獲得預期的結果。文字節點將被選中,而不是您要影響的元素。
再舉一個例子,如果您有一組特定的元素,您希望根據它們是否為空(沒有子節點)來對其執行某些操作,您可以使用類似 Node.hasChildNodes() 的方法檢查每個元素是否為空,但同樣,如果任何目標元素包含文字節點,您可能會得到錯誤的結果。
空白字元輔助函式
下面的 JavaScript 程式碼定義了幾個函式,使處理 DOM 中的空白字元變得更容易
/**
* Throughout, whitespace is defined as one of the characters
* "\t" TAB \u0009
* "\n" LF \u000A
* "\r" CR \u000D
* " " SPC \u0020
*
* This does not use JavaScript's "\s" because that includes non-breaking
* spaces (and also some other characters).
*/
/**
* Determine whether a node's text content is entirely whitespace.
*
* @param nod A node implementing the |CharacterData| interface (i.e.,
* a |Text|, |Comment|, or |CDATASection| node
* @return True if all of the text content of |nod| is whitespace,
* otherwise false.
*/
function is_all_ws(nod) {
return !/[^\t\n\r ]/.test(nod.textContent);
}
/**
* Determine if a node should be ignored by the iterator functions.
*
* @param nod An object implementing the DOM1 |Node| interface.
* @return true if the node is:
* 1) A |Text| node that is all whitespace
* 2) A |Comment| node
* and otherwise false.
*/
function is_ignorable(nod) {
return (
nod.nodeType === 8 || // A comment node
(nod.nodeType === 3 && is_all_ws(nod))
); // a text node, all ws
}
/**
* Version of |previousSibling| that skips nodes that are entirely
* whitespace or comments. (Normally |previousSibling| is a property
* of all DOM nodes that gives the sibling node, the node that is
* a child of the same parent, that occurs immediately before the
* reference node.)
*
* @param sib The reference node.
* @return Either:
* 1) The closest previous sibling to |sib| that is not
* ignorable according to |is_ignorable|, or
* 2) null if no such node exists.
*/
function node_before(sib) {
while ((sib = sib.previousSibling)) {
if (!is_ignorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of |nextSibling| that skips nodes that are entirely
* whitespace or comments.
*
* @param sib The reference node.
* @return Either:
* 1) The closest next sibling to |sib| that is not
* ignorable according to |is_ignorable|, or
* 2) null if no such node exists.
*/
function node_after(sib) {
while ((sib = sib.nextSibling)) {
if (!is_ignorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of |lastChild| that skips nodes that are entirely
* whitespace or comments. (Normally |lastChild| is a property
* of all DOM nodes that gives the last of the nodes contained
* directly in the reference node.)
*
* @param sib The reference node.
* @return Either:
* 1) The last child of |sib| that is not
* ignorable according to |is_ignorable|, or
* 2) null if no such node exists.
*/
function last_child(par) {
let res = par.lastChild;
while (res) {
if (!is_ignorable(res)) {
return res;
}
res = res.previousSibling;
}
return null;
}
/**
* Version of |firstChild| that skips nodes that are entirely
* whitespace and comments.
*
* @param sib The reference node.
* @return Either:
* 1) The first child of |sib| that is not
* ignorable according to |is_ignorable|, or
* 2) null if no such node exists.
*/
function first_child(par) {
let res = par.firstChild;
while (res) {
if (!is_ignorable(res)) {
return res;
}
res = res.nextSibling;
}
return null;
}
/**
* Version of |data| that doesn't include whitespace at the beginning
* and end and normalizes all whitespace to a single space. (Normally
* |data| is a property of text nodes that gives the text of the node.)
*
* @param txt The text node whose data should be returned
* @return A string giving the contents of the text node with
* whitespace collapsed.
*/
function data_of(txt) {
let data = txt.textContent;
data = data.replace(/[\t\n\r ]+/g, " ");
if (data[0] === " ") {
data = data.substring(1, data.length);
}
if (data[data.length - 1] === " ") {
data = data.substring(0, data.length - 1);
}
return data;
}
示例
以下程式碼演示瞭如何使用上述函式。它迭代元素(其所有子節點都是元素)的子節點,以查詢文字為 "This is the third paragraph" 的子節點,然後更改該段落的 class 屬性和內容。
let cur = first_child(document.getElementById("test"));
while (cur) {
if (data_of(cur.firstChild) === "This is the third paragraph.") {
cur.className = "magic";
cur.firstChild.textContent = "This is the magic paragraph.";
}
cur = node_after(cur);
}