
使用 OpenLLM 和 Vultr Cloud GPU 構建 AI 驅動的應用程式
OpenLLM 是一個開源平臺,可讓您建立支援 AI 的生產應用程式,例如個性化聊天機器人、推薦系統等。它允許您透過傳送 API 提示和引數來生成響應,以操縱響應。 OpenLLM 的庫包含所有主要模型,如 Mistral、Falcon 和 Llama。
在本文中,我們將演示如何在 Vultr GPU 伺服器上使用 OpenLLM 部署 Falcon 7B 模型來生成 API 響應,這些響應可用於建立支援 AI 的應用程式。您將學習如何安裝必需的依賴項以及如何建立具有永續性的 OpenLLM 服務。此外,我們將介紹如何將 Nginx 配置為反向代理以實現高效的負載均衡,並使用安全套接字層 (SSL) 證書保護您的應用程式以啟用 HTTPS。
在 Vultr 上部署伺服器
要高效地部署人工智慧 (AI) 或機器學習 (ML) 支援的應用程式,使用雲 GPU 是最有效的方法之一。雲 GPU 提供對最新技術的訪問,使您能夠持續構建、部署和全域性服務大規模應用程式。
-
註冊並登入 Vultr 客戶門戶。
-
導航到產品頁面。
-
從側邊選單中,選擇計算。
-
點選中心的部署伺服器按鈕。
-
選擇雲 GPU 作為伺服器型別。
-
選擇A40 作為 GPU 型別。
-
在“伺服器位置”部分,選擇您選擇的區域。
-
在“作業系統”部分,選擇Vultr GPU Stack 作為作業系統。
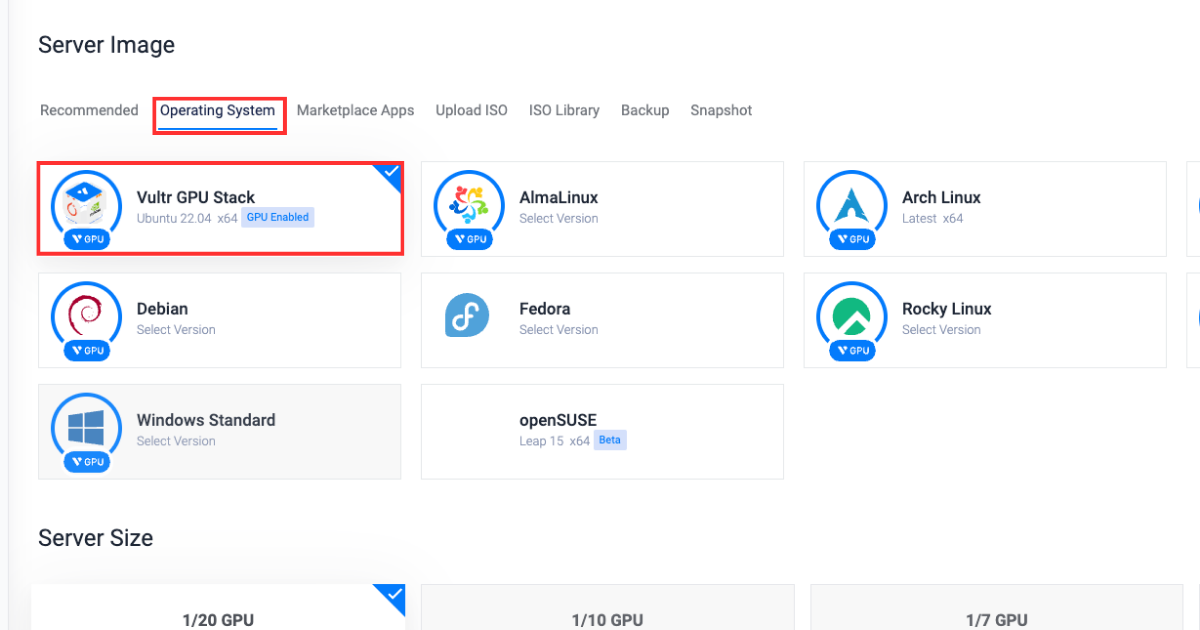
Vultr GPU Stack 旨在透過提供一套全面的預裝軟體(包括 NVIDIA CUDA Toolkit、NVIDIA cuDNN、Tensorflow、PyTorch 等)來簡化構建人工智慧 (AI) 和機器學習 (ML) 專案的過程。
-
在“伺服器大小”部分,選擇48 GB 選項。
-
在“附加功能”部分,根據需要選擇任何其他功能。
-
點選右下角的立即部署按鈕。
安裝必需的軟體包
根據前面的說明設定 Vultr 伺服器後,本節將指導您安裝執行 OpenLLM 所需的依賴 Python 包並驗證安裝。
-
安裝必需的軟體包。
bashpip3 install openllm scipy xformers einops每個軟體包代表的含義如下:
xformers:為構建基於 Transformer 的模型提供多種構件。einops:重塑和減少多維陣列的維度。scipy:解決複雜的數學問題,並具有操作和視覺化資料的能力。openllm:提供執行 OpenLLM 服務所需的依賴項。
-
驗證安裝。
bashopenllm -h如果安裝成功,系統將找到並執行
openllm,顯示其幫助資訊。這表明openllm已正確安裝並被系統識別。如果openllm未正確安裝,該命令很可能會返回錯誤。
建立 OpenLLM 服務
在本節中,您將學習如何建立一個 OpenLLM 服務,該服務將在系統啟動時自動啟動服務,並執行 Falcon 7B 模型進行推理。
-
獲取
openllm路徑。bashwhich openllm -
複製並貼上路徑到剪貼簿。您將在第 4 步中使用它。
-
建立 OpenLLM 服務檔案。
bashnano /etc/systemd/system/openllm.service -
將以下內容貼上到服務檔案中。請確保將
User和Group值替換為您實際的值。還將WorkingDirectory替換為 OpenLLM 路徑(不包括您之前複製的openllm),並將Execstart替換為包含可執行二進位制檔案的實際 OpenLLM 路徑。bash[Unit] Description= Daemon for OpenLLM Demo Application After=network.target [Service] User=example_user Group=example_user WorkingDirectory=/home/example_user/.local/bin/ ExecStart=/home/example_user/.local/bin/openllm start tiiuae/falcon-7b --backend pt [Install] WantedBy=multi-user.target -
啟動服務。
bashsystemctl start openllm -
驗證服務狀態。
bashsystemctl status openllm輸出將如下所示
● openllm.service - Daemon for OpenLLM Demo Application Loaded: loaded (/etc/systemd/system/openllm.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2023-11-29 20:51:25 UTC; 12min ago Main PID: 3160 (openllm) Tasks: 257 (limit: 72213) Memory: 21.9G CGroup: /system.slice/openllm.service ├─3160 /usr/bin/python3 /usr/local/bin/openllm start tiiuae/falcon-7b --backend pt -
啟用服務,以便在系統每次啟動時自動啟動。
bashsystemctl enable openllm
將 Nginx 配置為反向代理伺服器
Nginx 在您的 Web 伺服器和客戶端之間充當反向代理。它根據您的請求配置設定來路由傳入的請求。
在本節中,您將學習如何為 OpenLLM 應用程式配置反向代理,以使用 Nginx 實現高效的請求處理和負載均衡。您還將學習如何配置 OpenLLM 本身以實現反向代理功能。
-
登入 Vultr 客戶門戶。
-
導航到產品頁面。
-
從側邊選單中,展開網路下拉選單,然後選擇DNS。
-
點選中心的新增域名按鈕。
-
透過選擇您的伺服器 IP 地址,按照設定過程新增您的域名。
-
在您的域名註冊商處將以下主機名設定為您域名的主和輔助名稱伺服器。
- ns1.vultr.com
- ns2.vultr.com
-
安裝 Nginx。
bashsudo apt install nginx -
在
sites-available目錄中建立一個名為openllm.conf的檔案。bashsudo nano /etc/nginx/sites-available/openllm.conf -
將以下內容貼上到
openllm.conf檔案中。請確保將example.com替換為您實際的域名。bashserver { listen 80; listen [::]:80; server_name example.com www.example.com; location / { proxy_pass http://127.0.0.1:3000/; } }以上虛擬主機配置中使用了以下指令:
server:定義我們域名的設定塊。listen:指示伺服器在埠80上監聽傳入的請求。server_name:指定此伺服器塊將響應的域名。location:定義伺服器應如何處理傳入的請求。proxy_pass:指示伺服器將請求轉發到另一個位置,在本例中是http://127.0.0.1:3000/。
-
儲存檔案,然後退出編輯器。
-
透過將
openllm.conf檔案連結到sites-enabled目錄來啟用虛擬主機配置。bashsudo ln -s /etc/nginx/sites-available/openllm.conf /etc/nginx/sites-enabled/ -
測試配置以找出錯誤。
bashsudo nginx -t如果配置沒有錯誤,您的輸出應如下所示:
bashnginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful -
重啟 Nginx 伺服器。
bashsudo systemctl reload nginx -
允許埠
80上的傳入連線。bashsudo ufw allow 80/tcp
使用 Certbot 安裝 SSL 證書
Certbot 允許您從“Let's Encrypt”(一個免費證書頒發機構)獲取 SSL 證書。這些 SSL 證書充當加密金鑰,可在使用者和 Web 伺服器之間實現安全通訊。
在本節中,您將學習如何為您的域名請求“Let's Encrypt”的免費 SSL 證書,併為您的應用程式實現 HTTPS。您還將學習如何設定證書在 90 天內到期前自動續訂。
-
允許埠
443上的傳入連線以實現 HTTPS。bashsudo ufw allow 443/tcp -
使用
snap包管理器安裝certbot包。bashsudo snap install --classic certbot -
為您的域名請求新的 SSL 證書。請確保將
example.com替換為您實際的域名。bashsudo certbot --nginx -d example.com -d www.example.com -
您可以在以下連結中訪問 OpenLLM API 文件:
urlhttps://example.com
使用 OpenLLM 生成 API 響應
在配置了 Nginx 和 SSL 之後,本節將指導您向負責從給定提示生成響應的 OpenLLM 端點發送 API POST 請求。
向 API 端點發送 curl 請求。
curl -X POST -H "Content-Type: application/json" -d '{
"prompt": "What is the meaning of life?",
"stop": ["\n"],
"llm_config": {
"max_new_tokens": 128,
"min_length": 0,
"early_stopping": false,
"num_beams": 1,
"num_beam_groups": 1,
"use_cache": true,
"temperature": 0.75,
"top_k": 15,
"top_p": 0.9,
"typical_p": 1,
"epsilon_cutoff": 0,
"eta_cutoff": 0,
"diversity_penalty": 0,
"repetition_penalty": 1,
"encoder_repetition_penalty": 1,
"length_penalty": 1,
"no_repeat_ngram_size": 0,
"renormalize_logits": false,
"remove_invalid_values": false,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_scores": false,
"encoder_no_repeat_ngram_size": 0,
"logprobs": 0,
"prompt_logprobs": 0,
"n": 1,
"presence_penalty": 0,
"frequency_penalty": 0,
"use_beam_search": false,
"ignore_eos": false,
"skip_special_tokens": true
},
"adapter_name": null
}' https://example.com/v1/generate
您可以透過更改各種引數的值來調整響應的強度。以下是每個引數作用的解釋:
top_p:負責選擇輸出的最佳機率標記,使輸出更具針對性和相關性。epsilon_cutoff:負責忽略機率低於 epsilon 值的標記,從而忽略低機率選項。diversity_penalty:負責影響輸出的多樣性。較高的引數值將產生更多樣化且重複性較低的響應。repetition_penalty:負責對生成輸出中連續重複的標記施加懲罰。length_penalty:負責控制響應的長度;較高的引數值會生成更長的響應,反之亦然。no_repeat_ngram_size:負責懲罰在響應中已出現過的 n-gram(n 個標記的序列)的標記。remove_invalid_values:負責從生成響應中自動刪除具有無效值的標記。num_return_sequences:負責控制模型在響應中應生成的不同序列的數量。frequency_penalty:負責操縱模型在生成響應時選擇某些標記的頻率。use_beam_search:如果引數值設定為 true,則負責使用束搜尋查詢用於響應生成的相關續寫。ignore_eos:如果引數值設定為 true,則負責在生成響應時忽略“句子結束”標記。n:代表每個生成響應中的標記數量。
這是 curl 請求的示例輸出:
{
"prompt": "What is the meaning of life?",
"finished": true,
"outputs": [
{
"index": 0,
"text": " What is the meaning of the universe? How does the universe work?",
"token_ids": [
1634, 304, 248, 4113, 275, 248, 10314, 42, 1265, 960, 248, 10314, 633,
42, 193, 1265, 960, 248, 10314, 633, 42, 193
],
"cumulative_logprob": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"prompt_token_ids": [1562, 304, 248, 4113, 275, 1063, 42],
"prompt_logprobs": null,
"request_id": "openllm-e1b145f3e9614624975f76e7fae6050c"
}
總結
在本文中,您學習瞭如何使用 OpenLLM 和 Vultr GPU Stack 為 AI 驅動的應用程式構建 API 響應。本教程指導您完成了建立 OpenLLM 服務的步驟,該服務初始化了生成響應所需的模型和 API 端點。您還學習瞭如何將 Nginx 設定為 OpenLLM 服務的反向代理伺服器,並使用 SSL 證書對其進行保護。
這是一篇由 Vultr 贊助的文章。Vultr 是全球最大的私營雲計算平臺。Vultr 是開發者的首選,已為 185 個國家/地區的 150 萬多客戶提供了靈活、可擴充套件、全球化的雲計算、雲 GPU、裸金屬和雲端儲存解決方案。瞭解更多關於 Vultr 的資訊。